The following options are included in each of the five Big Data dialogs.
Sample Big Data Dialog, Data Tab
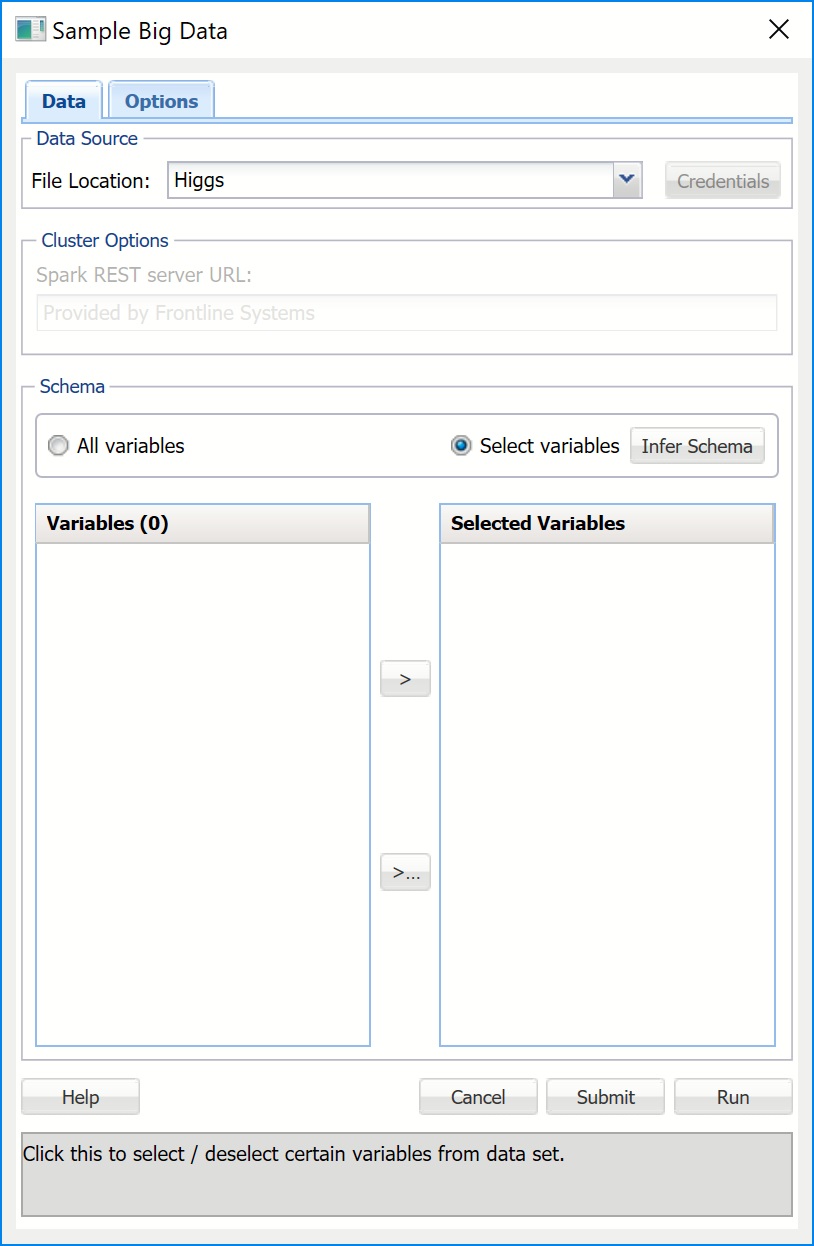
File Location
Enter the location of the file here.
Credentials
If your data set is located on Amazon S3, click Credentials to enter your Access and Secret Keys.
Schema
When All variables is selected for this option, all columns (features) in the data set would be selected for the analysis without the need for the user to select the variables.
When Select variables is selected for this option, the command button Infer Schema is enabled. Once Infer Schema is clicked, schema (variables) will be inferred from the data set on the cluster, and displayed in the Variables list. Use the > and < buttons to select variables for inclusion in the sample.
Variables
Variables available for inclusion in the sample appear here. Use the > button to select variables to be included in the sample.
Selected Variables
Variables transferred here are included in the sample. Use the < button to remove variables from the sample.
Submit
Clicking Submit sends a request for sampling to the compute cluster, but does not wait for completion. The result is a worksheet containing the Job ID and basic information about the submitted job so different submissions may be identified. This information can be used at any time later for querying the status of the job and generating reports based on the results of the completed job.
Run
Sends a request for sampling to the Apache Spark compute cluster where the Frontline Systems access server is installed and waits for the results. Once the job is completed and results are returned to the Analytic Solver Data Science client, a report is inserted into the Excel workbook to the right of the active worksheet.
Cancel
Click this button to close the open dialog without saving any options or creating an output report.
Help
Click this button to open the Analytic Solver Data Science Help Text.
Sample Big Data Dialog, Options Tab
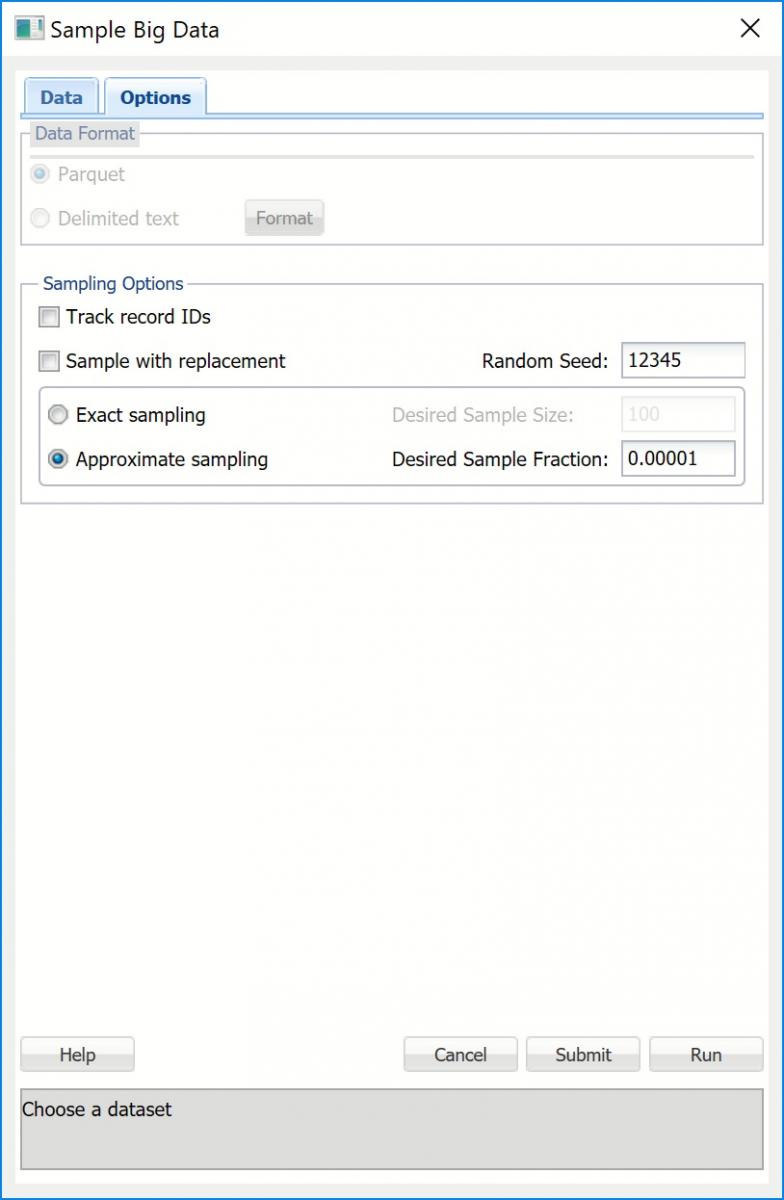
 Data Format
Data Format
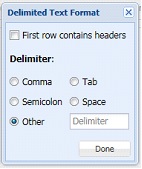
If your data is in Apache Parquet format, select Parquet for this option. If your data is in Delimited text format, select Delimited text. When Delimited text is selected, the Format button will be enabled. Click, to open the Delimited Text Format dialog. Here you can specify if your First row contains headers along with the delimiter used in your data.
Analytic Solver Data Science can process data from Hadoop Distributed File System (HDFS), local file systems that are visible to Spark cluster and Amazon S3. Performance is best with HDFS, and it is recommended that you load data from a local file system or Amazon S3 into HDFS. If the local file system is used, the data must be accessible at the same path on all Spark workers, either via a network path, or because it was copied to the same location on all workers.
At present, Analytic Solver Data Science can process data in Apache Parquet and CSV (delimited text) formats. Performance is far better with Parquet, which stores data in a compressed, columnar representation; it is highly recommended that you convert CSV data to Parquet before you seek to sample or summarize the data.
Track record IDs
If this option is selected, data records in the resulting sample will carry the correct ordinal IDs that correspond to the original data records, so that records can be matched. Note: Selecting this option may significantly increase running time so it should be applied only when necessary.
Sample with replacement
When selected, records in the dataset may be chosen for inclusion in the sample multiple times.
Random Seed
If an integer value appears for Random seed, Analytic Solver Data Science will use this value to set the feature selection random number seed. Setting the random number seed to a nonzero value ensures that the same sequence of random numbers is used each time the dataset is chosen for sampling. The default value is “12345”. If left blank, the random number generator is initialized from the system clock, so the random sample would be represented by different records from run to run. If you need the results from successive samples to be strictly comparable, you should set the seed. To do this, type the desired number you want into the box. This option accepts positive integers with up to 7 digits.
Exact sampling
When this option is selected, Analytic Solver Data Science will return a fixed - size sampled subset of data according to the setting for Desired Sample Size.
Desired Sample Size
Enter the number of records to be included in the sample.
Approximate sampling
When this option is selected, the size of the resultant sample will be determined by the value entered for Desired Sample Fraction. Approximate sampling is much faster than Exact Sampling. Usually, the resultant fraction is very close to the Desired Sample Fraction so this option should be preferred over exact sampling as often as possible. Even if the resultant sample slightly deviates from the desired size, this would be easy to correct in Excel.
Desired Sample Fraction
This is the expected size of the sample as a fraction of the dataset's size. If Sampling with Replacement is selected, the value for Desired Sample Fraction is the expected number of times each record can be chosen and must be greater than 0. If Sampling without replacement (i.e. Sampling with Replacement is not selected), the Desired Sample Fraction becomes the probability that each element is chosen and, as a result, Desired Sample Fraction must be between 0 and 1.
Big Data: Get Results Dialog
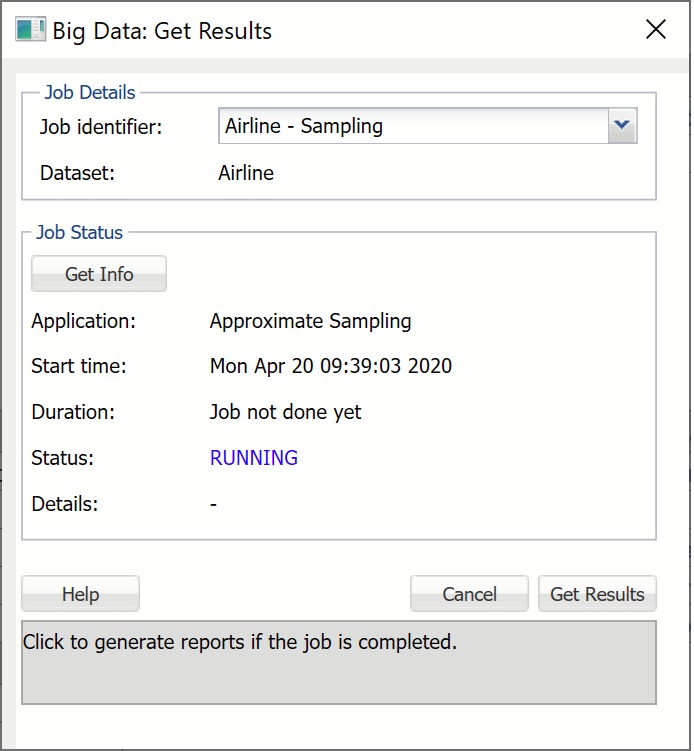
Job Identifier
Click the down arrow to obtain results from the previously submitted (using Get Data - Big Data - Sample/Summarize) job.
Get Info
Click this button to check the status of the previously submitted job. The following information will be returned.
Application is the type of the submitted job.
Start Time displays the date and time when the job was submitted. Start Time will always be displayed in the user's local time.
Duration shows the elapsed time since job submission if the job is still RUNNING, and total compute time if the job is FINISHED.
Status is the current state of the job: FINISHED, FAILED, ERRORED, or RUNNING. FINISHED indicates that the job has been completed and results are available for retrieval. FAILED or ERRORED indicates that the job has not completed due to an internal cluster failure. When this occurs, Details contain a message indicating the reason.
Get Results
If Status is FINISHED, click the Get Results button to obtain the results from the cluster and populate the report as shown below. Note: It is not required to click Get Info before Get Results. If Get Results is clicked, the status of the job will be checked and if the status is FINISHED, the results are pulled from the cluster, and the report is created. Otherwise, Status will be updated with the appropriate message to reflect the status: FAILED, ERRORED, or RUNNING.
Cancel
Click this command button to close the open dialog without saving any options or creating an output report.
Help
Click this command button to open the Analytic Solver Data Science Help Text.
Summarize Big Data Dialog, Data Tab
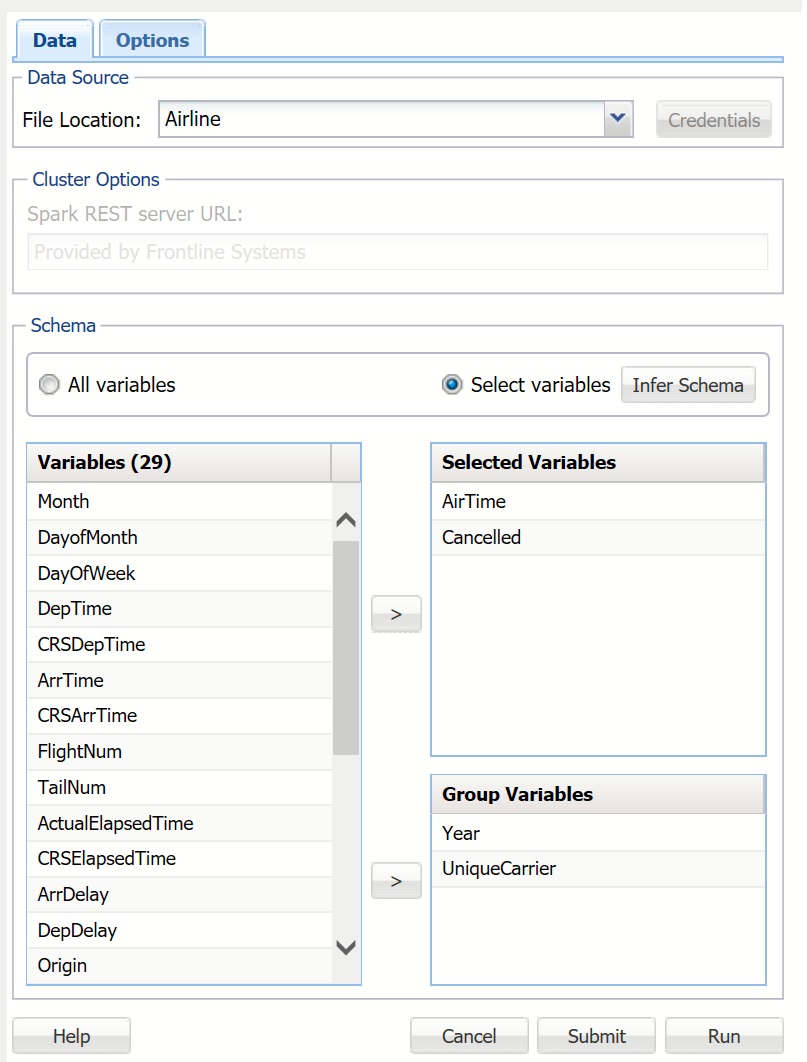
See the Sample Big Data, Data Dialog above for a description of all options shown on this dialog except Group Variables (described below).
Group Variables
Group Variables are variables from the data set that are treated as key variables for aggregation. In the screenshot above, two variables have been selected as Group Variables: Year and UniqueCarrier. The variables will be grouped so that all records with the same Year and UniqueCarrier are included in the same group, and then all aggregate functions for each group will be calculated.
Summarize Big Data Dialog, Options Tab
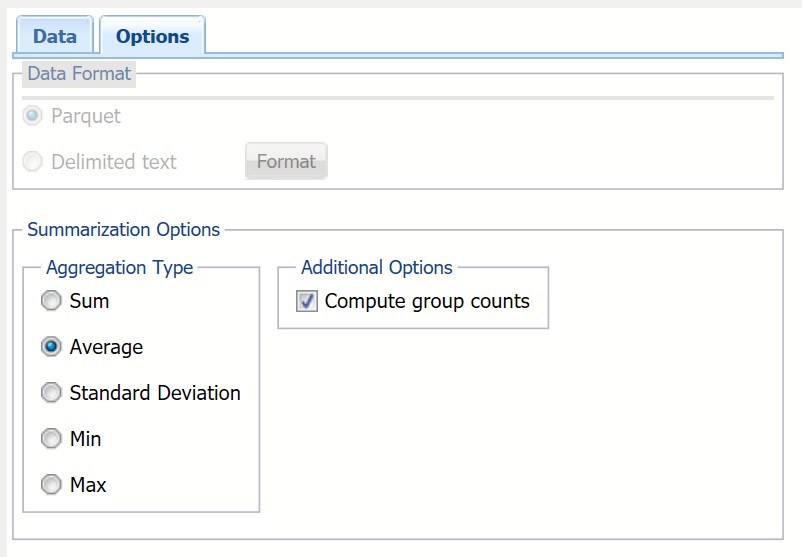
Aggregation Type
Aggregation Type provides five statistics that can be inferred from the data set: sum, average, standard deviation, minimum, and maximum.
Compute Group Counts
This option is enabled when one or more Group Variables exist. When this option is selected, the number of records belonging to each group is computed and reported