Introduction
One very important issue when fitting a model is how well the newly created model will behave when applied to new data. To address this issue, the dataset can be divided into multiple partitions: a training partition used to create the model, a validation partition to test the performance of the model and, if desired, a third test partition. Partitioning is performed randomly, to protect against a biased partition, according to proportions specified by the user or according to rules concerning the dataset type. For example, when creating a time series forecast, data is partitioned by chronological order.
Training Set
The training dataset is used to train or build a model. For example, in a linear regression, the training dataset is used to fit the linear regression model, i.e. to compute the regression coefficients. In a neural network model, the training dataset is used to obtain the network weights. After fitting the model on the training dataset, the performance of the model should be tested on the validation dataset.
Validation Set
Once a model is built using the training dataset, the performance of the model must be validated using new data. If the training data itself was utilized to compute the accuracy of the model fit, the result would be an overly optimistic estimate of the accuracy of the model. This is because the training or model fitting process ensures that the accuracy of the model for the training data is as high as possible -- the model is specifically suited to the training data. To obtain a more realistic estimate of how the model would perform with unseen data, we must set aside a part of the original data and not include this set in the training process. This dataset is known as the validation dataset.
To validate the performance of the model, Analytic Solver Data Science measures the discrepancy between the actual observed values and the predicted value of the observation. This discrepancy is known as the error in prediction and is used to measure the overall accuracy of the model.
Test Set
The validation dataset is often used to fine-tune models. For example, you might try out neural network models with various architectures and test the accuracy of each on the validation dataset to choose the best performer among the competing architectures. In such a case, when a model is finally chosen, its accuracy with the validation dataset is still an optimistic estimate of how it would perform with unseen data. This is because the final model has come out as the winner among the competing models based on the fact that its accuracy with the validation dataset is highest. As a result, it is a good idea to set aside yet another portion of data which is used neither in training nor in validation. This set is known as the test dataset. The accuracy of the model on the test data gives a realistic estimate of the performance of the model on completely unseen data.
Analytic Solver Data Science provides two methods of partitioning: Standard Partitioning and Partitioning with Oversampling. Analytic Solver Data Science provides two approaches to standard partitioning: random partitioning and user-defined partitioning.
Random Partitioning
In simple random sampling, every observation in the main dataset has equal probability of being selected for the partition dataset. For example, if you specify 60% for the training dataset, then 60% of the total observations are randomly selected for the training dataset. In other words, each observation has a 60% chance of being selected.
Random partitioning uses the system clock as a default to initialize the random number seed. Alternatively, the random seed can be manually set which will result in the same observations being chosen for the training/validation/test sets each time a standard partition is created.
User – defined Partitioning
In user-defined partitioning, the partition variable specified is used to partition the dataset. This is useful when you have already predetermined the observations to be used in the training, validation, and/or test sets. This partition variable takes the value: "t" for training, "v" for validation and "s" for test. Rows with any other values in the Partition Variable column are ignored. The partition variable serves as a flag for writing each observation to the appropriate partition(s).
Partition with Oversampling
This method of partitioning is used when the percentage of successes in the output variable is very low, e.g. callers who “opt in” to a short survey at the end of a customer service call. Typically, the number of successes, in this case, the number of people who finish the survey, is very low so information connected with these callers is minimal. As a result, it would be almost impossible to formulate a model based on these callers. In these types of cases, we must use Oversampling (also called weighted sampling). Oversampling can be used when there are only two classes, one of much greater importance than the other, i.e. callers who finish the survey as compared to callers who simply hang up.
Analytic Solver Data Science takes the following steps when partitioning with oversampling.
- The data is partitioned by randomly allocating 50% of the success values for the output variable to the training set. The output variable must be limited to two classes which can either be numbers or strings.
- Analytic Solver Data Science maintains the % success in training set specified by the user in the training set by randomly selecting the required records with failures.
- The remaining 50% of successes are randomly allocated to the validation set.
- If % validation data to be taken away as test data is selected, then Analytic Solver Data Science will create an appropriate test set from the validation set.
Partition Options
It is no longer always necessary to partition a dataset before running a classification or regression algorithm. Rather, you can now perform partitioning on the Parameters tab for each classification or regression method.

If the active data set is un-partitioned, the Partition Data command button, will be enabled. If the active data set has already been partitioned, this button will be disabled. Clicking the Partition Data button opens the following dialog. Select Partition Data on the dialog to enable the partitioning options.
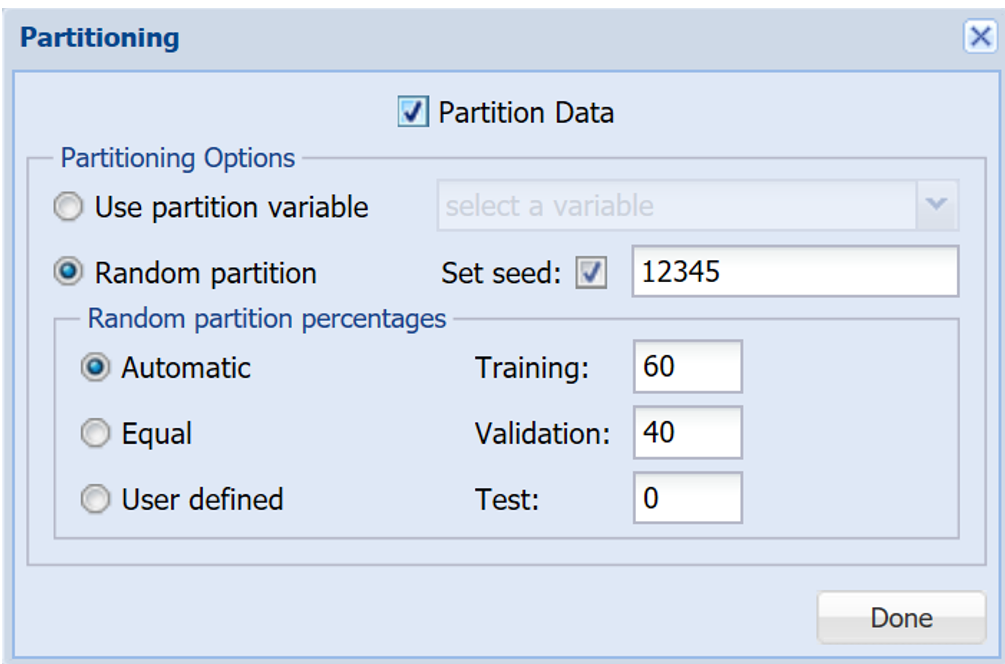
If a data partition will be used to train and validate several different classification or regression algorithms that will be compared for predictive power, it may be better to use the Ribbon Partition choices to create a partitioned dataset. But if the data partition will be used with a single algorithm, or if it isn’t crucial to compare algorithms on exactly the same partitioned data, “Partition-on-the-Fly” offers several advantages:
- User interface steps are saved, and the Analytic Solver task pane is not cluttered with partition output.
- Partition-on-the-fly is much faster than creating a standard partition and then running an algorithm.
- Partition-on-the-fly can handle larger datasets without exhausting memory, since the intermediate partition results for the partitioned data is never created.