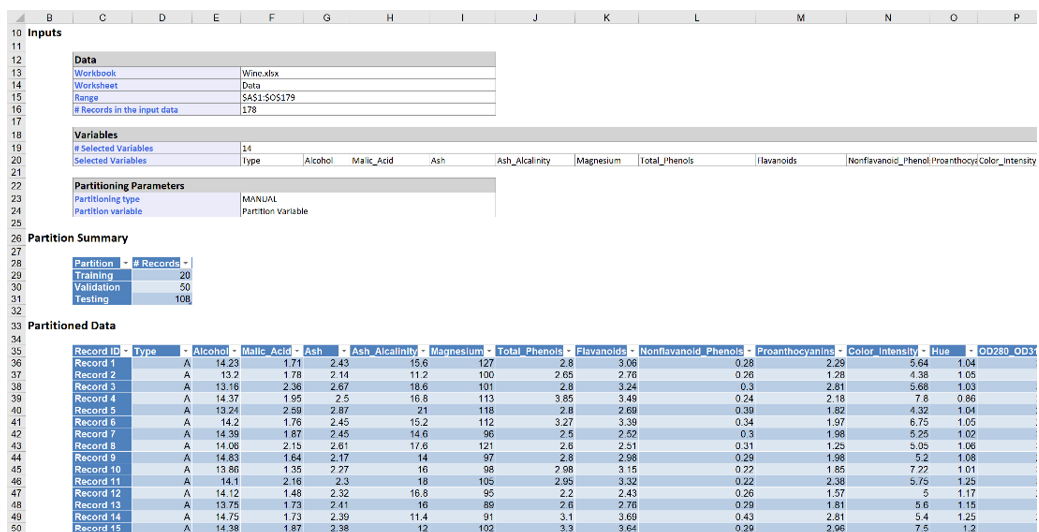
The example in this section illustrates how to use Analytic Solver Data Science’s partition utility to partition the example dataset, Wine.xlsx. Click Help – Example Models -- Forecasting/Data Science Examples to open.
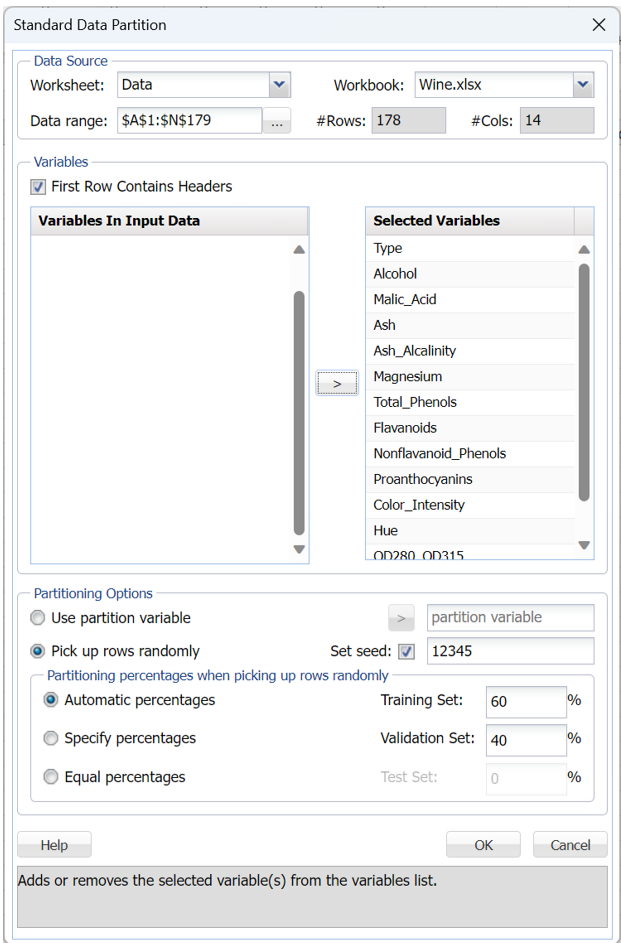
Click Partition – Standard Partition on the Data Science Ribbon. The Standard Data Partition dialog opens.
Highlight all variables in the Variables In Input Data list box, then click > to include them in the partitioned data. Then click OK to accept the remainder of the default settings. Sixty percent of the observations will be assigned to the Training set and forty percent of the observations will be assigned to the Validation set.
Standard Data Partition dialog
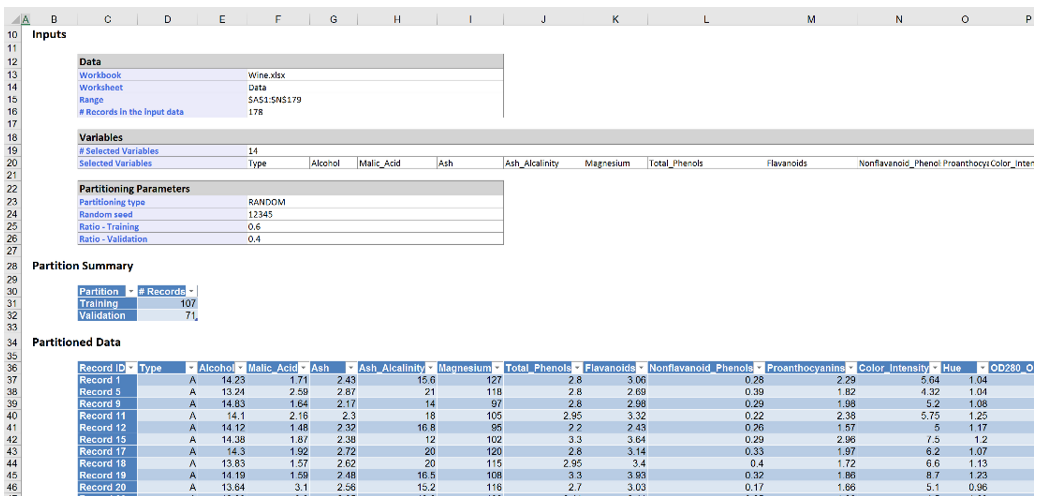
STDPartition inserted right of the Data worksheet.
107 observations were assigned to the training set and 71 observations were assigned to the validation set, or roughly 60% and 40% of the observations, respectively.
Under Partitioned Data, the first 107 records (rows 37 thru 143) are the records assigned to the training partition and the remaining 71 records (rows 144 thru 214) are the records assigned to the validation partition.
Standard Partitioning Results
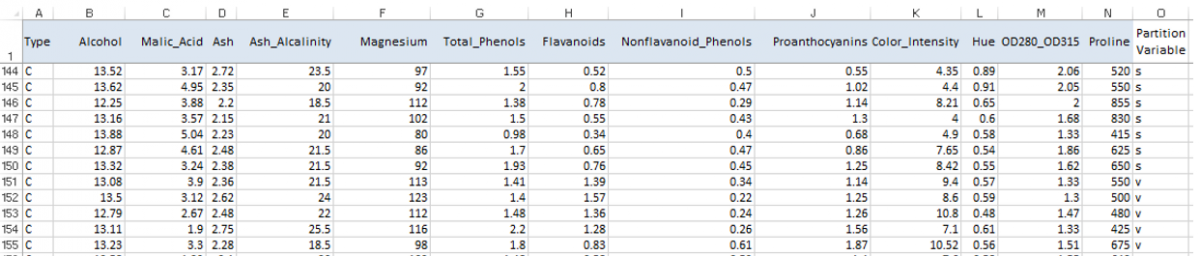
It is also possible for the user to specify which sets each observation should be assigned. In column O, enter a “t”, “v” or “s” to indicate the assignment of each record to either the training dataset (t), the validation dataset (v), or the test dataset (s), as shown in the screenshot below.
Wine Dataset with Partition Variable
Click Partition – Standard Partition on the Data Science ribbon to open the Standard Data Partition dialog.
Select Use Partition Variable in the Partitioning options section, select Partition Variable in the Variables list box, then click > next to Use Partition Variable. Analytic Solver Data Science will use the values in the Partition Variable column to create the training, validation, and test sets. Records with a “t” in the O column will be designated as training records. Records with a “v” in the O column will be designated as validating records and records with an “s” in this column will be designated as testing records. Now highlight all remaining variables in the list box and click > to include them in the partitioned data.
Standard Data Partition dialog with Partition Variable
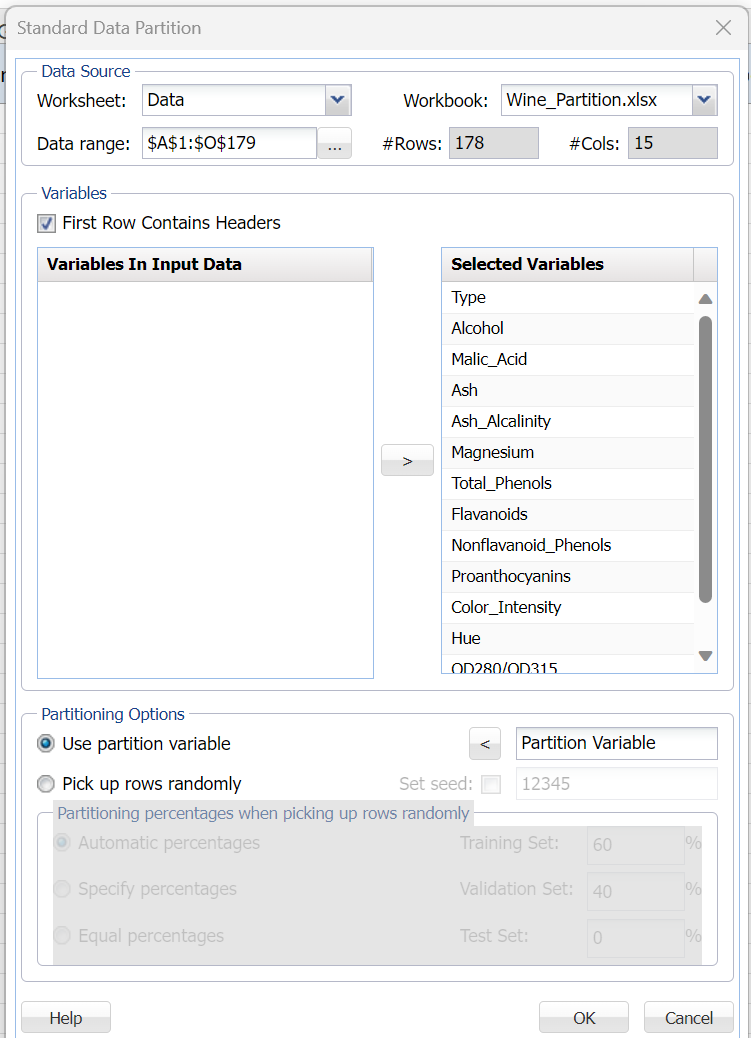
Click OK to create the partitions. STDPartition1 is inserted right. If you inspect the results, you will find that all records assigned a “t” now belong to the training set, all records assigned a “v” now belong to the validation set, and all records assigned an “s” now belong to the test set.
Results for Standard Data Partition using a Partition Variable