The following options appear on the Partitioning with Oversampling dialog.
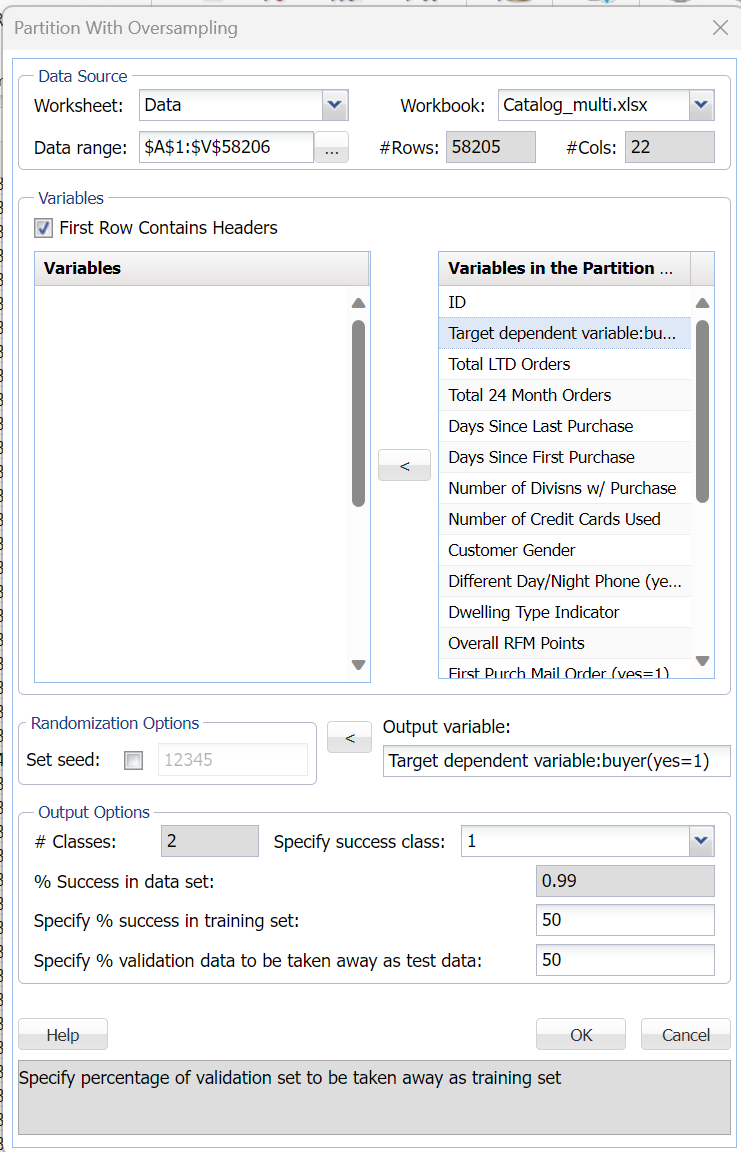
Set seed
Random partitioning uses the system clock as a default to initialize the random number seed. This option is not selected by default. Setting this option results in the same records being assigned to the same set on successive runs. The default seed entry is 12345.
Output variable
Select the output variable from the Variables in the Partition Data list.
#Classes
After the output variable is chosen, the number of classes (distinct values) for the output variable will be displayed here. Analytic Solver Data Science supports a class size of 2.
Specify success class
After the output variable is chosen, select the success value for the output variable here (i.e. 0 or 1 or yes or no).
% of success in data set
After the output variable is selected, the percentage of the number of successes in the dataset is listed here.
Specify % success in training set
Enter the percentage of successes to be assigned to the Training Set (default is 50%). With this setting, 50% of the successes will be assigned to the Training Set, and 50% will be assigned to the Validation Set.
Specify % validation data to be taken away as test data
If a test set is desired, specify the percentage of the validation set that should be allocated to the test set.