Neural Network Regression Options
The options below appear on one of the Neural Network Regression method dialog tabs.
Neural Network Regression dialog, Data tab
See below for options appearing on the Neural Network Regression – Data tab. Note: The Neural Network Automatic and Manual Regression – Data tabs are identical.
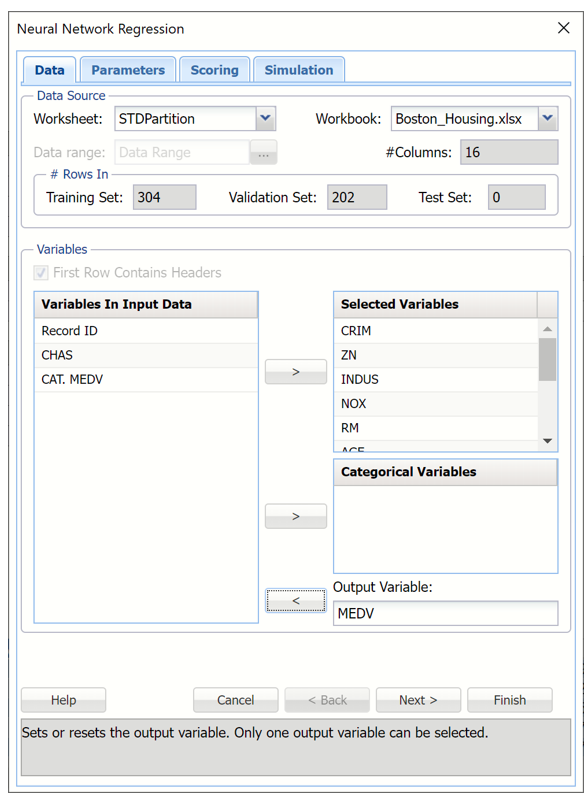
Variables In Input Data
All variables in the dataset are listed here.
Selected Variables
Variables listed here will be utilized in the Analytic Solver Data Science output.
Categorical Variables
Place categorical variables from the Variables list box to be included in the model by clicking the > command button. The Neural Network Regression algorithm will accept non-numeric categorical variables.
Output Variable
Select the variable whose outcome is to be predicted here.
See below for options appearing on the Neural Network Regression - Parameters dialog. Note: The Neural Network Automatic Regression - Parameters dialog does not include Architecture, but is otherwise the same.
Neural Network Regression dialog, Parameters tab
See below for options appearing on the Neural Network Regression – Parameters tab. Note: The Neural Network Automatic Regression – Parameters tab does not include Architecture, but is otherwise the same.
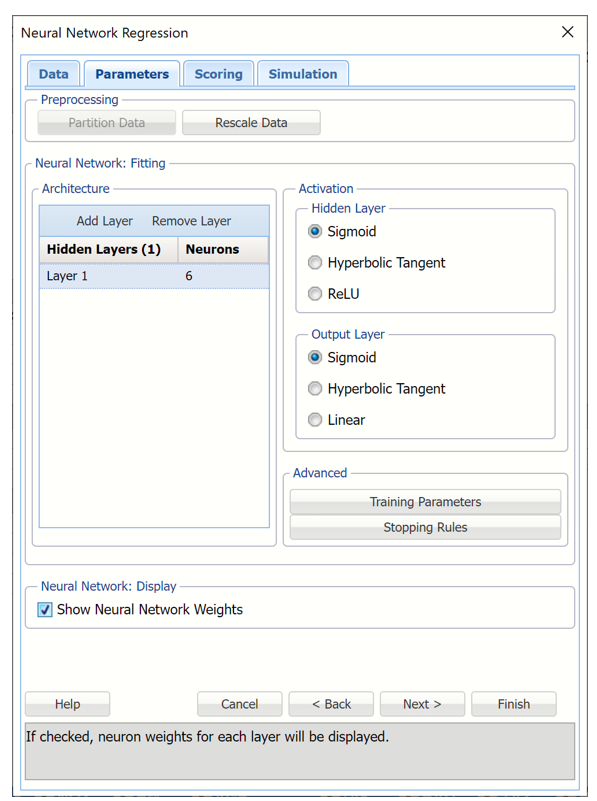
Partition Data
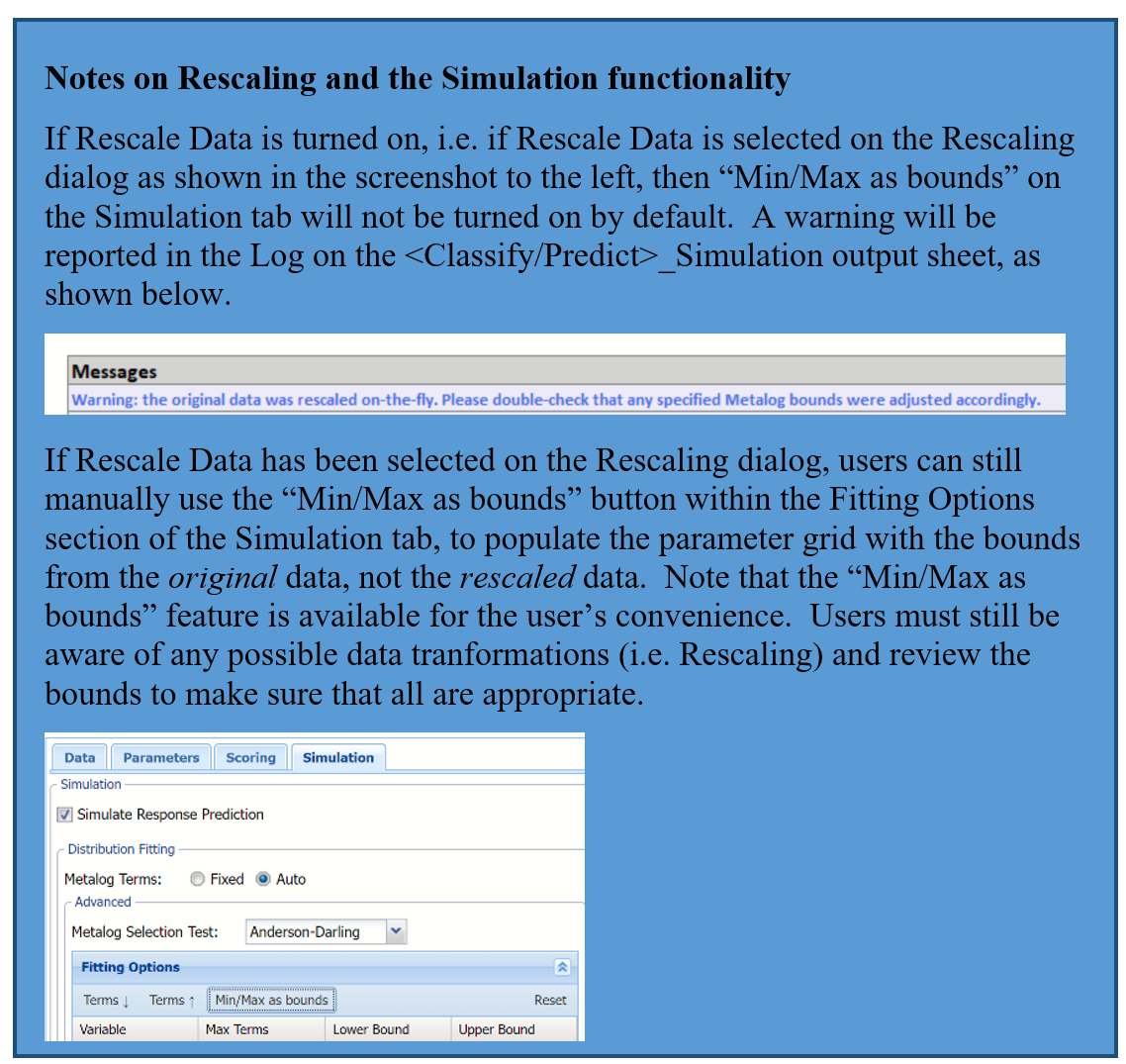
Analytic Solver Data Science includes the ability to partition a dataset from within a classification or regression (prediction) method by clicking Partition Data on the Parameters tab. Analytic Solver Data Science will partition your dataset (according to the partition options you set) immediately before running the regression method. If partitioning has already occurred on the dataset, this option will be disabled. See Partition Data for more information.
Rescale Data
Click Rescale Data to open the Rescaling dialog.

Use Rescaling to normalize one or more features in your data during the data preprocessing stage. Analytic Solver Data Science provides the following methods for feature scaling: Standardization, Normalization, Adjusted Normalization and Unit Norm. For more information on this new feature, see Rescale Continuous Data.
Hidden Layers/Neurons
Click Add Layer to add a hidden layer. To delete a layer, click Remove Layer. Once the layer is added, enter the desired Neurons.
Hidden Layer
Nodes in the hidden layer receive input from the input layer. The output of the hidden nodes is a weighted sum of the input values. This weighted sum is computed with weights that are initially set at random values. As the network "learns", these weights are adjusted. This weighted sum is used to compute the hidden node's output using a transfer function. Select Standard (the default setting) to use a logistic function for the transfer function with a range of 0 and 1. This function has a "squashing effect" on very small or very large values but is almost linear in the range where the value of the function is between 0.1 and 0.9. Select Symmetric to use the tanh function for the transfer function, the range being -1 to 1. If more than one hidden layer exists, this function is used for all layers. The default selection is Standard.
Output Layer
As in the hidden layer output calculation (explained in the above paragraph), the output layer is also computed using the same transfer function as described for Activation: Hidden Layer. Select Sigmoid (the default setting) to use a logistic function for the transfer function with a range of 0 and 1. Select Hyperbolic Tangent to use the tanh function for the transfer function, the range being -1 to 1. In neural networks, the Softmax function is often implemented at the final layer of a classification neural network to impose the constraints that the posterior probabilities for the output variable must be >= 0 and <= 1 and sum to 1. Select Softmax to utilize this function. The default selection is Standard.
Training Parameters
Click Training Parameters to open the Training Parameters dialog.
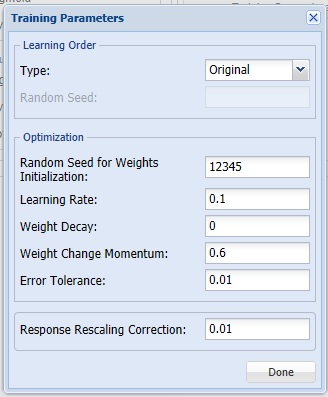
Learning Order [Original or Random]
This option specifies the order in which the records in the training dataset are being processed. It is recommended to shuffle the training data to avoid the possibility of processing correlated reocrds in order. It also helps the neural network algorithm to converge faster. If Random is selected, Random Seed is enabled.
Learning Order [Random Seed]
This option specifies the seed for shuffling the training records. Note that different random shuffling may lead to different results, but as long as the training data is shuffled, different ordering typically does not result in drastic changes in performance.
Random Seed for Weights Initialization
If an integer value appears for Random Seed for Weights Initialization, Analytic Solver Data Science will use this value to set the seed for the initial assignment of the neuron values. Setting the random number seed to a nonzero value (any number of your choice is OK) ensures that the same sequence of random numbers is used each time the neuron values are calculated. The default value is “12345”. If left blank, the random number generator is initialized from the system clock, so the sequence of random numbers will be different in each calculation. If you need the results from successive runs of the algorithm to another to be strictly comparable, you should set the seed. To do this, type the desired number you want into the box.
Learning Rate
This is the multiplying factor for the error correction during backpropagation; it is roughly equivalent to the learning rate for the neural network. A low value produces slow but steady learning, a high value produces rapid but erratic learning. Values for the step size typically range from 0.1 to 0.9.
Weight Decay
To prevent over-fitting of the network on the training data, set a weight decay to penalize the weight in each iteration. Each calculated weight will be multiplied by (1-decay).
Weight Change Momentum
In each new round of error correction, some memory of the prior correction is retained so that an outlier that crops up does not spoil accumulated learning.
Error Tolerance
The error in a particular iteration is backpropagated only if it is greater than the error tolerance. Typically error tolerance is a small value in the range from 0 to 1.
Response Rescaling Correction
This option specifies a small number, which is applied to the Normalization rescaling formula, if the output layer activation is Sigmoid (or Softmax in Classification), and Adjusted Normalization, if the output layer activation is Hyperbolic Tangent. The rescaling correction ensures that all response values stay within the range of activation function.
Stopping Rules
Click Stopping Rules to open the Stopping Rules dialog. Here users can specify a comprehensive set of rules for stopping the algorithm early plus cross-validation on the training error.
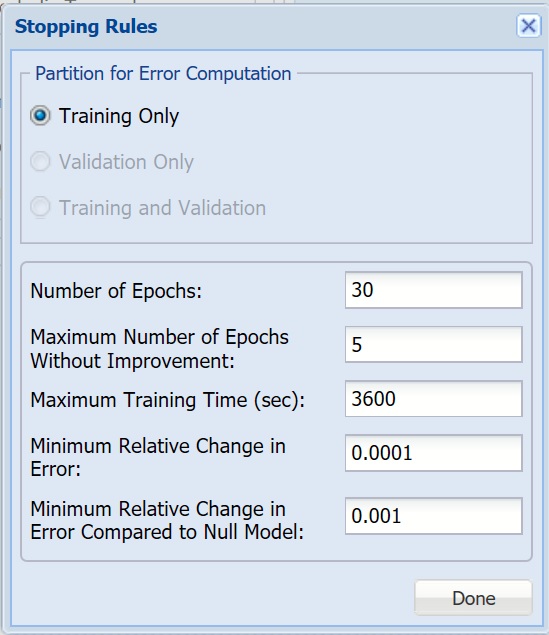
Partition for Error Computation
Specifies which data partition is used to estimate the error after each training epoch.
Number of Epochs
An epoch is one sweep through all records in the training set. Use this option to set the number of epochs to be performed by the algorithm.
Maximum Number of Epochs Without Improvement
The algorithm will stop after this number of epochs has been completed, and no improvement has ben realized.
Maximum Training Time
The algorithm will stop once this time (in seconds) has been exceeded
Keep Minimum Relative Change in Error
If the relative change in error is less than this value, the algorithm will stop.
Keep Minimum Relative Change in Error Compared to Null Model
If the relative change in error compared to the Null Model is less than this value, the algorithm will stop. Null Model is the baseline model used for comparing the performance of the neural network model.
Regression Tree Dialog, Scoring tab
See below for options appearing on the Neural Network Regression – Scoring tab. Note: This tab does not exist on the Neural Network Automatic Regression dialog.

Score Training Data
Select these options to show an assessment of the performance of the Neural Network in predicting the value of the output variable in the training partition.
When Frequency Chart is selected, a frequency chart will be displayed when the NNP_TrainingScore worksheet are selected. This chart will display an interactive application similar to the Analyze Data feature, and explained in detail in the Analyze Data chapter that appears earlier in this guide. This chart will include frequency distributions of the actual and predicted responses individually, or side-by-side, depending on the user’s preference, as well as basic and advanced statistics for variables, percentiles, six sigma indices.
Score Validation Data
These options are enabled when a validation data set is present. Select these options to show an assessment of the performance of the Neural Network in predicting the value of the output variable in the validation data. The report is displayed according to your specifications - Detailed, Summary, and Lift charts. When Frequency Chart is selected, a frequency chart (described above) will be displayed when the NNP_ValidationScore worksheet is selected.
Score Test Data
These options are enabled when a test set is present. Select these options to show an assessment of the performance of the Neural Network in predicting the value of the output variable in the test data. The report is displayed according to your specifications - Detailed, Summary, and Lift charts. When Frequency Chart is selected, a frequency chart (described above) will be displayed when the NNP_TestScore worksheet is selected.
Score New Data
See Scoring for more information on the options located in the Score Test Data and Score New Data groups.
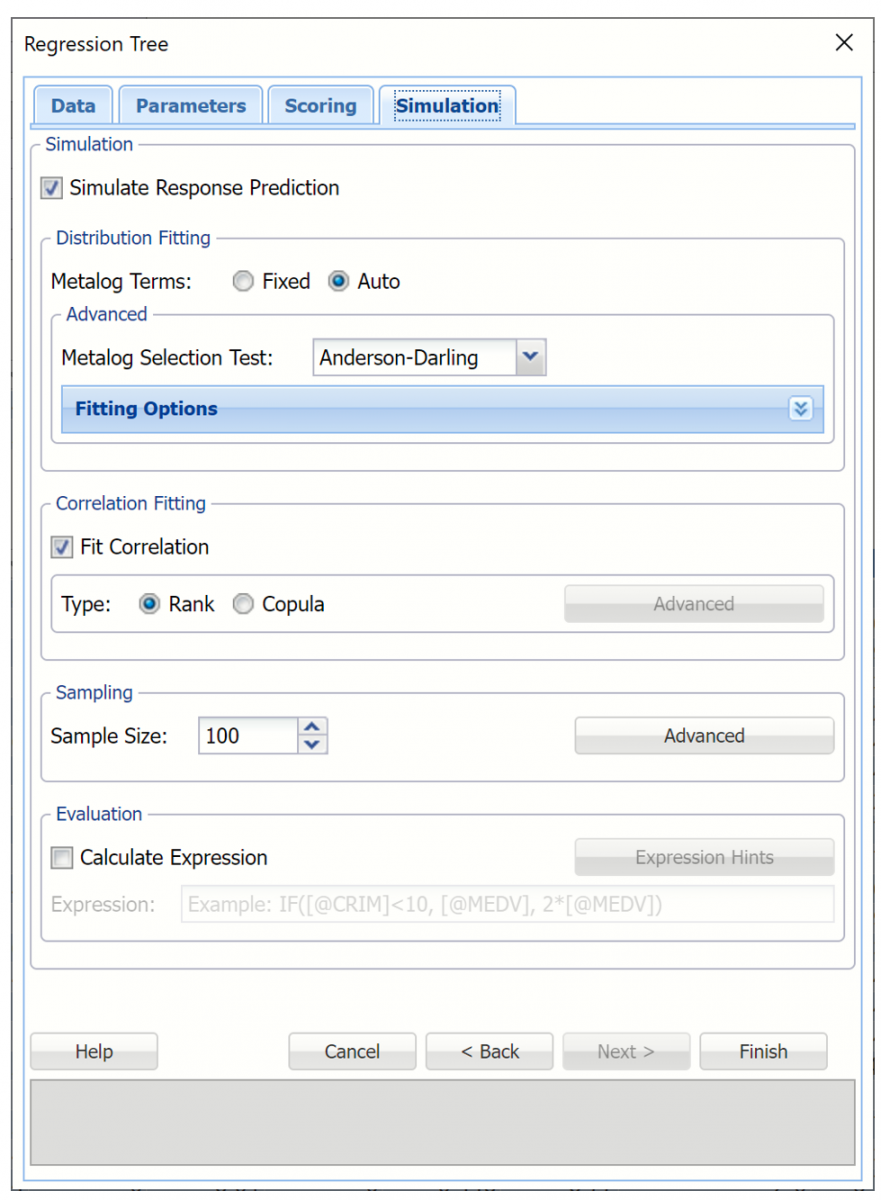
Regression Tree Dialog, Simulation tab
All supervised algorithms include a new Simulation tab. This tab uses the functionality from the Generate Data feature to generate synthetic data based on the training partition, and uses the fitted model to produce predictions for the synthetic data. The resulting report, NNP_Simulation, will contain the synthetic data, the predicted values and the Excel-calculated Expression column, if present. In addition, frequency charts containing the Predicted, Training, and Expression (if present) sources or a combination of any pair may be viewed, if the charts are of the same type. This tab is not supported in the Neural Network Regression Automatic dialog.
Evaluation: Select Calculate Expression to amend an Expression column onto the frequency chart displayed on the RT_Simulation output tab. Expression can be any valid Excel formula that references a variable and the response as [@COLUMN_NAME]. Click the Expression Hints button for more information on entering an expression.